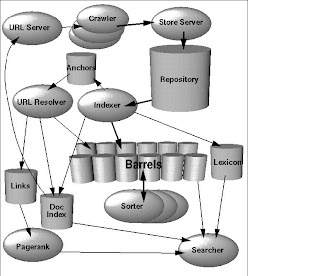
 Indexing the web content
Indexing the web contentSimilar to an index of a book, a search engine also extracts and builds a catalog of all the words that appear on each web page and the number of times it appears on that page etc. Indexing of web content is a challenging task assuming an average of 1000 words per web page and billions of such pages. Indexes are used for searching by keywords; therefore, it has to be stored in the memory of computers to provide quick access to the search results. Indexing starts with parsing the website content using a parser. Any parser, which is designed to run on the entire Web, must handle a huge array of possible errors. The parser can extract the relevant information from a web page by excluding certain common words (such as a, an, the - also known as stop words), HTML tags, Java Scripting and other bad characters. A good parser can also eliminate commonly occurring
content in the website pages such as navigation links, so that they are not counted as a part of the page'scontent. Once the indexing is completed, the results are stored in memory, in a sorted order. This helps in retrieving the information quickly. Indexes are updated periodically as new content is crawled. Some indexes help create a dictionary (lexicon) of all words that are available for searching. Also a lexicon helps in correcting mistyped words by showi ng the corrected versions in a search result. A part of the success of the search engine lies in how the indexes are built and used. Various algorithms are used to optimize these indexes so that relevant results are found easily without much computing resource usage.
Indexing the web contentSimilar to an index of a book, a search engine also extracts and builds a catalog of all the words that appear on each web page and the number of times it appears on that page etc. Indexing of web content is a challenging task assuming an average of 1000 words per web page and billions of such pages. Indexes are used for searching by keywords; therefore, it has to be stored in the memory of computers to provide quick access to the search results. Indexing starts with parsing the website content using a parser. Any parser, which is designed to run on the entire Web, must handle a huge array of possible errors. The parser can extract the relevant information from a web page by excluding certain common words (such as a, an, the - also known as stop words), HTML tags, Java Scripting and other bad characters. A good parser can also eliminate commonly occurring
content in the website pages such as navigation links, so that they are not counted as a part of the page'scontent. Once the indexing is completed, the results are stored in memory, in a sorted order. This helps in retrieving the information quickly. Indexes are updated periodically as new content is crawled. Some indexes help create a dictionary (lexicon) of all words that are available for searching. Also a lexicon helps in correcting mistyped words by showi ng the corrected versions in a search result. A part of the success of the search engine lies in how the indexes are built and used. Various algorithms are used to optimize these indexes so that relevant results are found easily without much computing resource usage.
Storing the Web ContentIn addition to indexing the web content, the individual pages are also stored in the search engine'
database. Due to cheaper disk storage, the storage capacity of search engines is very huge, and often runs into terabytes of data. However, retrieving this data quickly and efficiently requires special distributed and scalable data storage functionality. The amount of data, that a search engine can store, is limited by the amount of data it can retrieve for search results. Google can index and store about 3 billion web documents. This capacity is far more than any other search engine during this time. "Spiders" take a Web page'scontent and create key search words that enable online users to find pages they're looking for.
In addition to indexing the web content, the individual pages are also stored in the search engine'sdatabase. Due to cheaper disk storage, the storage capacity of search engines is very huge, and often runs into terabytes of data. However, retrieving this data quickly and efficiently requires special distributed and scalable data storage functionality. The amount of data, that a search engine can store, is limited by the amount of data it can retrieve for search results. Google can index and store about 3 billion web documents. This capacity is far more than any other search engine during this time. "Spiders" take a Web page'scontent and create key search words that enable online users to find pages they're looking for.


